Week 10 [Fri, Mar 17th] - Topics
Guidance for the item(s) below:
Previously, you learned:
- Three basic design quality aspects: abstraction, coupling, cohesion
- Some design principles (e.g., Single Responsibility Principle) that aim to improve those aspects.
This week, we cover design patterns, a concept that builds upon the above.
Introduction
Guidance for the item(s) below:
Now that you know what design pattern is, let's learn a few example design patterns.
Singleton pattern
Can explain the Singleton design pattern
Context
Certain classes should have no more than just one instance (e.g. the main controller class of the system). These single instances are commonly known as singletons.
Problem
A normal class can be instantiated multiple times by invoking the constructor.
Solution
Make the constructor of the singleton class private, because a public constructor will allow others to instantiate the class at will. Provide a public class-level method to access the single instance.
Example:

The <<Singleton>> in the class above uses the UML stereotype notation, which is used to (optionally) indicate the purpose or the role played by a UML element. In this example, the class Logic is playing the role of a Singleton class. The general format is <<role/purpose>>.
Facade pattern
Can explain the Facade design pattern
Context
Components need to access functionality deep inside other components.
The UI component of a Library system might want to access functionality of the Book class contained inside the Logic component.
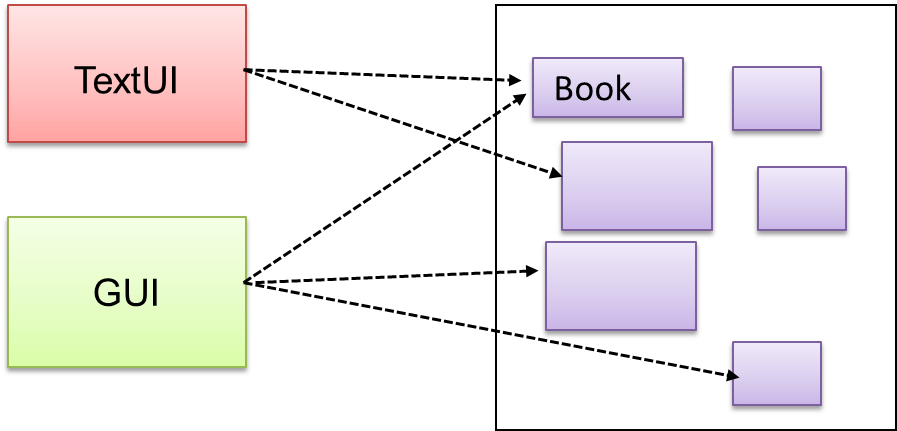
Problem
Access to the component should be allowed without exposing its internal details. e.g. the UI component should access the functionality of the Logic component without knowing that it contains a Book class within it.
Solution
Include a class that sits between the component internals and users of the component such that all access to the component happens through the Facade class.
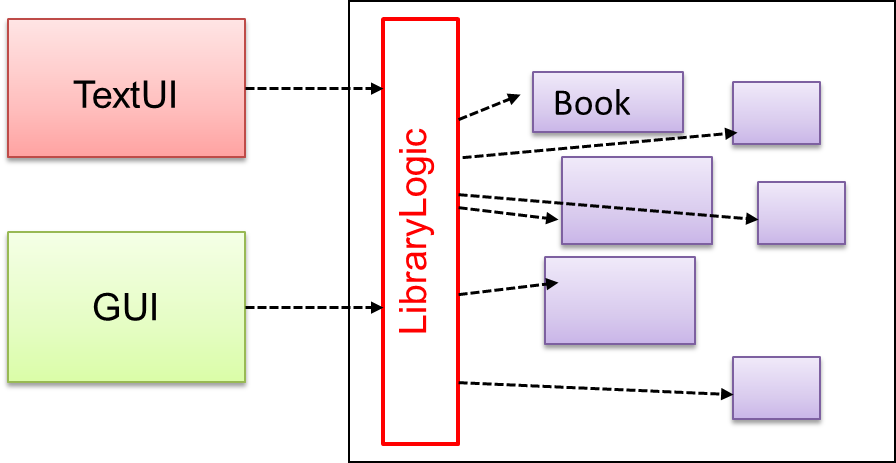
The following class diagram applies the Facade pattern to the Library System example. The LibraryLogic class is the Facade class.
Command pattern
Can explain the Command design pattern
Context
A system is required to execute a number of commands, each doing a different task. For example, a system might have to support Sort, List, Reset commands.
Problem
It is preferable that some part of the code executes these commands without having to know each command type. e.g., there can be a CommandQueue object that is responsible for queuing commands and executing them without knowledge of what each command does.
Solution
The essential element of this pattern is to have a general <<Command>> object that can be passed around, stored, executed, etc without knowing the type of command (i.e. via polymorphism).
Let us examine an example application of the pattern first:
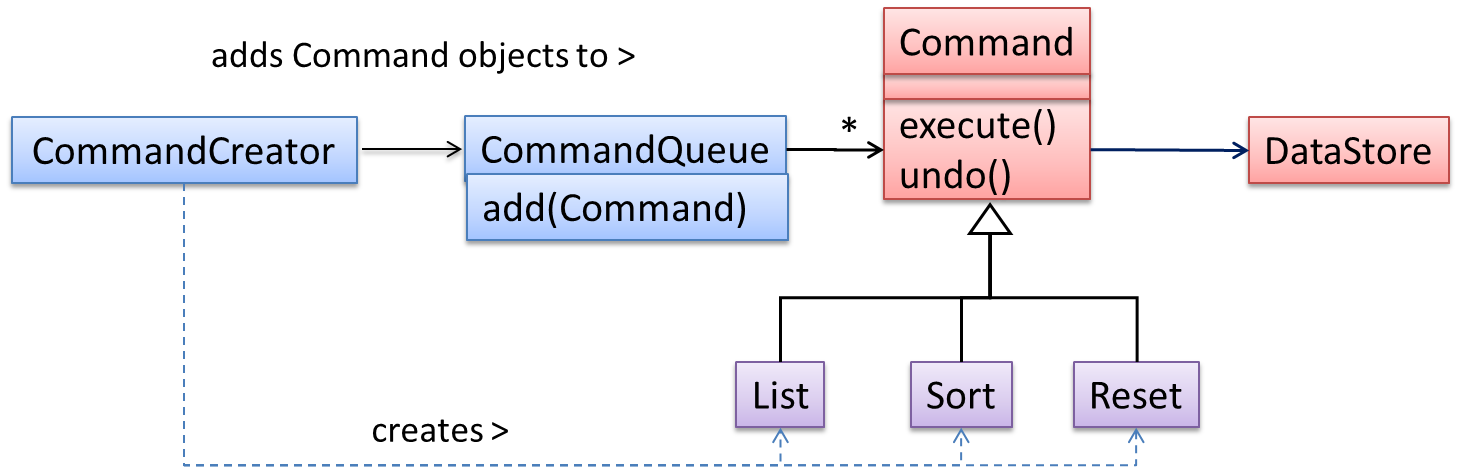
In the example solution below, the CommandCreator creates List, Sort, and Reset Command objects and adds them to the CommandQueue object. The CommandQueue object treats them all as Command objects and performs the execute/undo operation on each of them without knowledge of the specific Command type. When executed, each Command object will access the DataStore object to carry out its task. The Command class can also be an abstract class or an interface.
The general form of the solution is as follows.
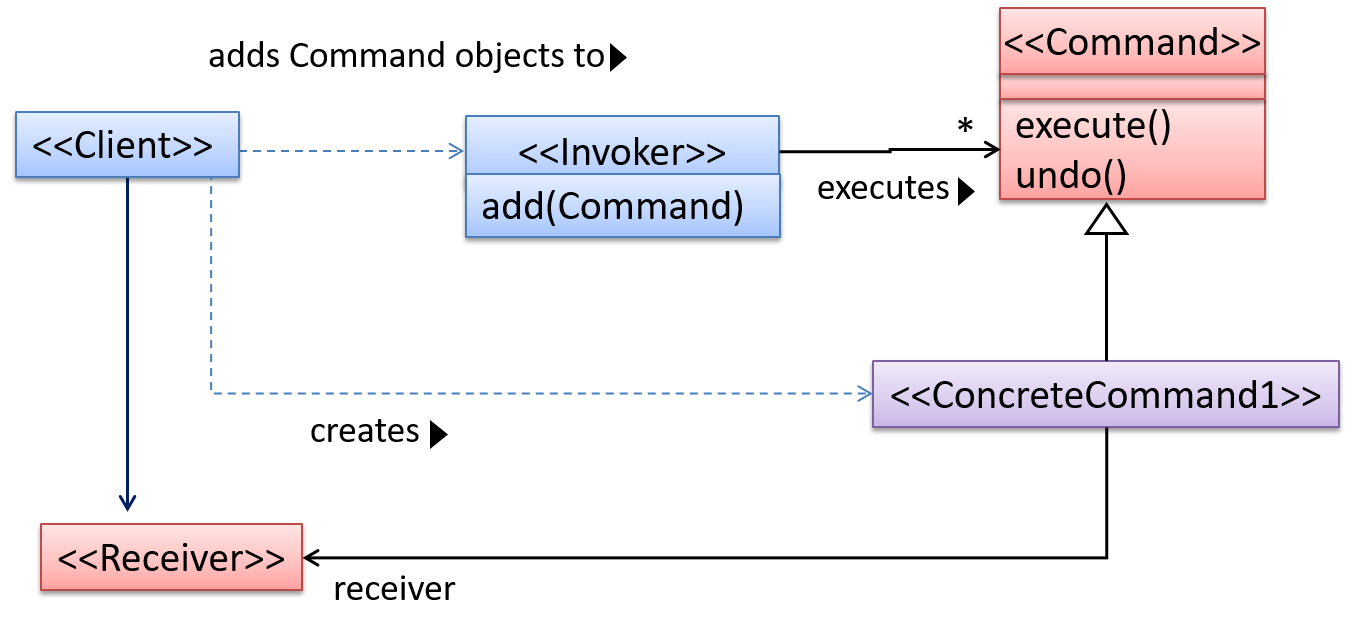
The <<Client>> creates a <<ConcreteCommand>> object, and passes it to the <<Invoker>>. The <<Invoker>> object treats all commands as a general <<Command>> type. <<Invoker>> issues a request by calling execute() on the command. If a command is undoable, <<ConcreteCommand>> will store the state for undoing the command prior to invoking execute(). In addition, the <<ConcreteCommand>> object may have to be linked to any <<Receiver>> of the command ( ) before it is passed to the <<Invoker>>. Note that an application of the command pattern does not have to follow the structure given above.
Abstraction Occurrence pattern
Follow up notes for the item(s) above:
A couple of more design patterns will be covered next week.
Guidance for the item(s) below:
You already know some techniques (e.g., exceptions, assertions) to make the code more resilient to errors. Given next is an overarching approach to coding that aims to push further in that direction.
Can use defensive coding to enforce compulsory associations
Consider two classes, Account and Guarantor, with an association as shown in the following diagram:
Example:

Here, the association is compulsory i.e. an Account object should always be linked to a Guarantor. One way to implement this is to simply use a reference variable, like this:
class Account {
Guarantor guarantor;
void setGuarantor(Guarantor g) {
guarantor = g;
}
}
However, what if someone else used the Account class like this?
Account a = new Account();
a.setGuarantor(null);
This results in an Account without a Guarantor! In a real banking system, this could have serious consequences! The code here did not try to prevent such a thing from happening. You can make the code more defensive by proactively enforcing the multiplicity constraint, like this:
class Account {
private Guarantor guarantor;
public Account(Guarantor g) {
if (g == null) {
stopSystemWithMessage(
"multiplicity violated. Null Guarantor");
}
guarantor = g;
}
public void setGuarantor(Guarantor g) {
if (g == null) {
stopSystemWithMessage(
"multiplicity violated. Null Guarantor");
}
guarantor = g;
}
// ...
}
Guidance for the item(s) below:
Previously, we learned how to measure test coverage. This week, we look into how to increase coverage with the least number of test cases.
First, we take a look at test case design in general, different approaches to test case design, and few different categorization of test cases.
Guidance for the item(s) below:
Next, a heuristic used for improving the quality of test cases.
Guidance for the item(s) below:
Previously, you learned about equivalence partitions, a heuristic for dividing the possible test cases into partitions. But which test cases should we pick from each partition? Next, let us learn another heuristic which can addresses that problem.